


I suck at drawing, always have. I thought this would limit my artistic expression to producing music forever...
Until powerful text2image AI like #dalle and #StableDiffusion became publicly available in August 2022!
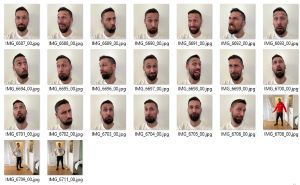
I used a bit of Sunday playtime to get my hands dirty with this tech. The header contains a few of the outputs I generated using #StableDiffusion and: It's impressive! Let me share my thoughts below.
It's a really difficult problem to solve:
From the GAN technology trigger (2014) over artistic style transfer (2015) to style-based face generation (2018) to powerful DallE text2image (2021) to the #StableDiffusion tech used here (2022) this took 8 years and a tremendous amount of work by a gigantic community of coders, software and hardware companies.
It's easy and quick to train:
20min googling, 20min for a dozen of selfies, 20min setup, 20min training and you are ready to go
It's cheap and available to everyone:
I trained on free GPUs in google Colab but non-coders can use iphone apps offering training for 10$ per face
It's brittle and frustrating to use:
All above being said, only 10% of the outputs are OK and 10% of those are flawless. Training on two faces and then trying to get a good composition with no errors on either face is very tricky as the errors multiply. Nonetheless, its a great starting point for artists to work-off from and get inspiration.




It shows how important data-privacy is:
Do you have a video showing your face online available to the public? Congratulations! Now, everyone can create fake images of you! While I grew up in the goldilocks phase of the rise of social media where people warned of the consequences of sharing too much information openly. With this tech another possibility for fraud is added to the long list of problematic outcomes possible with the right data in the wrong hands. Gen-Z is luckily more aware of the consequences of others owning your data.
It's impressive how deep the models are:
The amount of variety and artistic styles encoded within this 2GB model is tremendous. Hierarchical encoding is a concept well known in our own brain (e.g. single neurons encode abstract concepts such as thinking, seeing or hearing Jennifer Aniston, 2005) but tinkering on the couch with a 2GB "silicon brain" really gives you an impression of what the deep in deep learning refers to and to how much more crazy our brains actually are.
It's a Pandora's box for society:
Copyright for the artists? Ethics of manipulating any face in any context? Currently its still wild-west and a gold rush. The company behind the model raised after 1 year in existence already 100M$+. Text2video, localized models (e.g. for Bollywood content in India) alongside privatized power to censor media content will hit the fan within the next years.
It's just the beginning:
Text-to-image is very easy to use for humans as we can immediately verify the quality of the desired output. But what about other much less intuitive data sources? DNA-to-brain function, DNA-to-Protein structure, Protein-structure-to-Toxicity, Citation-to-future science, City planning-to-climate change impact, ...?
My Conclusion:
Text-to-image is a great way for many people to explore the current possibilities and boundaries of the technology. Wherever there are connected datasets a similar user experience of interfacing with AI could help people to easily explore the variable space and discover worthwhile opportunities to pursue. This in-silico playfully gained intuition for what concepts and factors matter in highly complex datasets (i.e. text2image as above) could reduce the amount of actual costly and time-intensive experiments (i.e. learning how to draw the painting from scratch) also in other data rich domains in biosciences, medicine and text.
How to do it yourself
Training
No need to reinvent the wheel, just follow this well done video:
Where to get ideas?
Amazing website for prompts: https://lexica.art
Example outputs
After 1000 iteration training using the input dataset above using the prompts in the respective gallery description. "Toph Person" is the instance_prompt that were associated with my facial features during training. You can find it in each of the below prompts as otherwise the AI would choose a random face.































So very impressive outputs although after some time I was not sure anymore how I really look like. The outputs often are veeeery close to the real thing and certainly hit the uncanny valley in most other cases. Emotions are often pretty hard to get right, so blank stare worked best for now.
Other faces
Redoing the same process with my wife resulted in a standalone model for her alone with the following results:








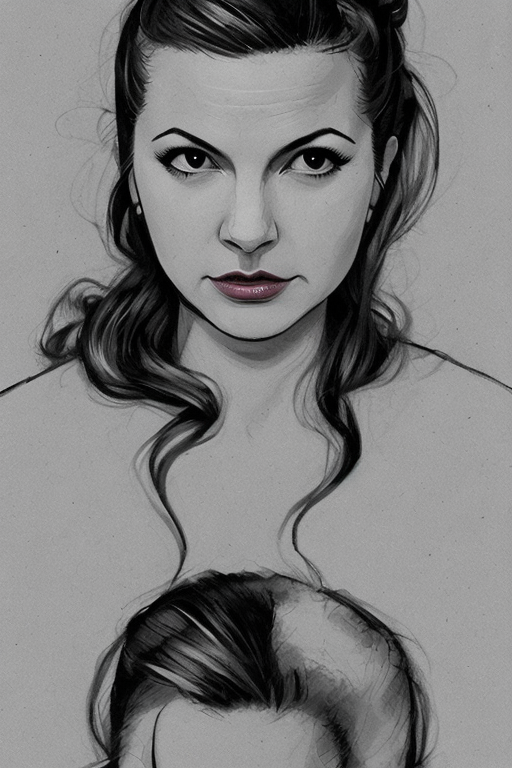
What about multiple people?
Ok, so each alone worked very well, but how to do family portraits? For this we need to again train a fresh model using both training sets within a single training run.
Proclaim both concepts prior to training and then use both instance prompts together as below:
concepts_list = [
{
"instance_prompt": "asiczka",
"class_prompt": "person",
"instance_data_dir": "/content/data/asiczka",
"class_data_dir": "/content/data/person"
},
{
"instance_prompt": "toph",
"class_prompt": "person",
"instance_data_dir": "/content/data/toph",
"class_data_dir": "/content/data/person"
}
]
Example_couple_prompt = "a vintage couples portrait photo of toph person standing next to a asizcka person..."





This is where this hits a roadblock for me as the time required to get any good output is too long. Better training schedule and more and quicker sampling of results might help but I guess this will improve rapidly over the next few months.


