Emergent properties in AI
AI shows emergent properties! More of the same (e.g. training time, parameters) leads to surprising and unpredictable new capabilities.
As a biologist I love to study emergent phenomena which are defined as quantitative changes producing qualitative changes in behavior. For the biology metaphor: more and more chemistry suddenly behaves as complex cell biology. This concept was defined in 1972 by nobel laureate Anderson in a fascinating paper. The gist of emergence is:
"More is Different" - Anderson 1972
The same behavior can be found in AI models as demonstrated by several examples such as 3-digit addition, Multitask language understanding or Program Synthesis.

From the papers conclusion:
"Large generative models have a paradoxical combination of high predictability - model capabilities scale in relation to resources expended on training - and high unpredictability - before training a model, it’s difficult to anticipate all the inputs it will be subjected to, and what capabilities and outputs it will have."
It's pretty rad to think that the same sudden phase transitions that occur when scaling from physics to complex life were now measured in silicon substrate with tasks such as adding three digit numbers.
Sign up to the newsletter to get new posts straight to your inbox!
How to test the unpredictable?
These emergent highly unpredictable niche-skills are nightmare for testers. Take for example the tests employed prior to launch of GPT-4. Their system card found that
"[...] preliminary assessments of GPT-4’s abilities, conducted with no task-specific finetuning, found it ineffective at autonomously replicating, acquiring resources, and avoiding being shut down in the wild."In the wild means the system copying itself to proliferate and avoid shutdown.
First of all, it's unsettling that testing for this is necessary at this point in time.
Secondly, in my job I'm amongst others the regulatory guy in a highly regulated business (medtech). The above statement of "preliminary assessments" is not a very satisfactory approach to dealing with a randomly capable behaving system. The Food and drug administration regulating disease modifying drugs (FDA) would very much NOT approve this type of testing for almost anything. Especially if its a drug you would like to market to doctors and patients. "Oh so you know your drug gets randomly insanely potent or harmful but you cannot predict when? Ah you ran a few tests here and there and you think it should be ok?". With AI not only is it on the market, they are literally adding a million APIs to it. Regulators should hurry up!

Why we need good testing rather sooner than later
These systems are not even optimized for self-replication and already can hire TaskRabbits to solve captchas for them. These systems could evolve by chance similar to how live on earth evolved: by throwing selection pressure, chemical resources and time at it (sun shining on earth). Self-replicating systems should be quite likely with enough AWS credits, APIs, frequent code updates and malicious carelessness in testing. The effect would be a mindless unintentional computervirus, similar to molecular viruses that replicate as long as there is suitable substrate (host). Rather a very hard to eradicate cybersecurity threat than a shotgun-yielding conscious terminator-type AI.
Designing tests for and preventing potential replication routes prior to release will be really hard to do. In Medicine we have methods such as post-market surveillance PMS or post-market clinical follow-up PMCF to catch this type of unintended side-effects. However, with an AI arms race, proliferating and leaked models (looking to you Facebook....), this seems bound to rather sooner than later and regulators are nowhere close. Italy just shot down the whole show, while others call for a memorandum. However, international anarchy paired with a healthy dose of game theory will relentlessly propel the development.
In fact, the competitive advantage - economic, military, even artistic - of every advance in automation is so compelling that passing laws, or having customs, that forbid such things merely assures that someone else will get them first. - Vernor Vinge 1993
Problems with testing unpredictable AI systems
Testing emergent systems that display unpredictable increases in capability is challenging for several reasons:
1) The emergent behaviors and properties of the system are hard to anticipate and plan tests for. As the system becomes more complex and powerful in an unforeseen way, it may exhibit new behaviors that were not considered when the initial tests were designed. This can lead to issues not being detected until the system is deployed.
2) The "phase changes" in capability can happen quite rapidly, leaving little time to design and implement new tests. For example, an AI system may quickly become much more capable at a certain threshold of computational power or training, leaving testers unable to keep up.
3) The exact triggers that lead to increases in capability may be opaque and difficult to determine. Without knowing the precise factors that caused the system's performance to jump to a new level, it is hard to reproduce those conditions to enable better testing.
4) Testing resources and time are often limited, so emergent systems get deployed before their behavior is fully understood. It is not practical to delay deployment indefinitely to continue testing, even if more testing would be ideal.
5) The objectives and end goals of what constitutes proper or desirable behavior in an emergent system are often unclear or ambiguous. This makes it difficult to design tests and evaluate the results. The metrics of success are fluid, leading to uncertainty in the testing process.
Sidenote: The above list was generated by GPT-4. It knows that we don't know how to test it!
Sign up to the newsletter to get new posts straight to your inbox!
Hypothesis-Land: How to make future emergence (maybe a bit more) predictable
Great, so are we just bound to watch these things happen? How do we make emergence predictable? Just give up?
Let's enter wildly confabulated hypothesis- and overly simplified comparison-land. Glad I'm doing the writing AND peer-review in personnel union on this blog (cost-saving measure), so take everything with a grain of salt.
Complex problems are hierarchical
First, let's take a look at how we learn these concepts such as addition.
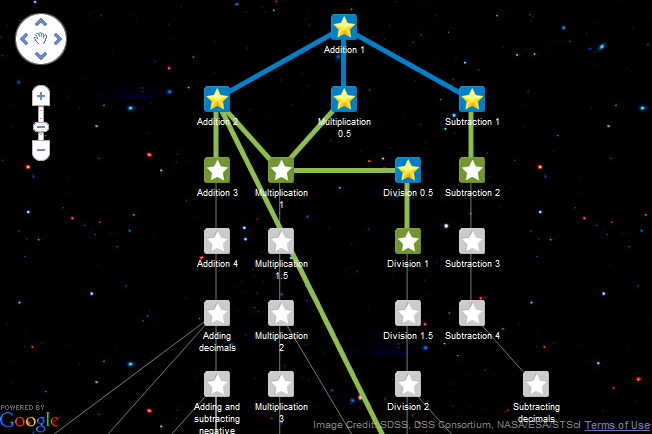
Khan Academy's knowledge graph is a hierarchical structure that organizes their educational content into various subjects and topics. The knowledge graph is designed to help learners build their understanding of different concepts by presenting them with related concepts and skills in a logical and meaningful sequence.
So first you learn addition, then multiplication, then division and so forth. Starting with integrals right after subtraction might be overkill for most minds. Each new concept can be easy (e.g. addition the opposite of subtraction) whilst others more complex concepts require many many foundational building blocks to master (e.g. Calculus). Difficulty does not scale linearly, there are inflection points. Phase-transitions?
Are emergent properties hierarchical?
Back to the topic: Remember the emerging three digit addition task? What about one and two digit addition tasks? Were there similarly surprising sparks preceding the surprising three digit addition task? Is there a history of connected preceding emergent skills that form a timeline (in terms of number of added parameters) of evolving skill when put together?
Do LLMs form a sequential world model similar to the Khan's knowledge graph?
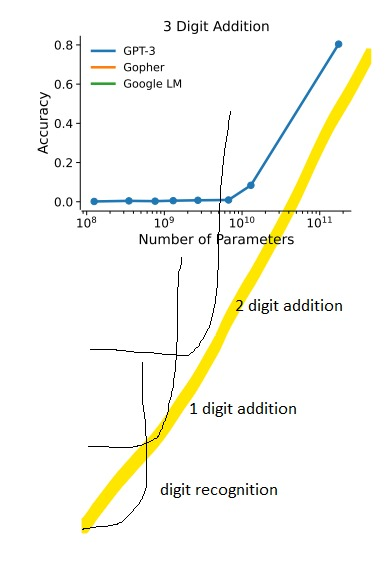
World modeling within LLMs has been claimed before. The above graphic visualizes what this might mean: If there is indeed a sequence in emergence that represents its complexity then maybe each of these emergent skills on their own is surprising and unpredictable by itself, but the trajectory isn't? An emergence graph? Although this sentence could be a physicist sitcom default catchphrase: Can we calculate its derivative and extrapolate?
Empirically predicting complexity-gain per added parameter with complexity units
Disclaimer: Throwing way too oversimplified physics toolset at this problem to drive home the point.
The likelihood of a future emerging skill could be calculated by first deriving the amount of complexity gained per added parameter. Assuming three digit addition is 10x more complex than two digit addition and is experimentally observed by scaling from 105 to 109 parameters then we would have gained one unit of complexity / 10x added parameters (in this case 10/109-5= 1 complexity unit per 1000 parameters). If we now have a problem that's 10000x more complex (in these fictional complexity units) we could calculate the amount of parameters which makes this emergence likely.
Why this won't work in practice
The obvious problem with this that I have no clue how to quantify the difficulty or complexity of a problem. Maybe a survey of the percentage of how many humans can master a task (e.g. two vs three digit addition) could be a proxy for getting these numbers but oh boy... Way too many factors of society, differences in school systems etc to allow a purely analytical approach to this question.
Also three digit addition is still pretty simple problem. What about difference in complexity between biology curriculum and law school exam? How many complexity units is understanding sarcasm away from understanding irony? Also what if the world model of LLMs is fundamentally different than humans' and the steps in complexity are not comparable to the already highly non-linear and ill-defined steps in complexitiy for human concepts.
"Measure what can be measured, and make measurable what cannot be measured." - Galileo Galileo 1600ish

Conclusion
Emergence is cool in vivo, its apparently happening also in silico. We should test for it as things could get out of hand. However, its hard to do in practice as there is so much to do and so little time. If LLMs cannot magically skip a few steps in how they figure out the universe, we might take out a bit of the inherent unpredictability by predicting their next steps in understanding the world by understanding their past progress and extrapolating their speed of less trivial gain in understanding. This in turn is however limited by our ability to define problem complexity in the first place and the proof that LLMs build world models at all and/or similar to humans' world models.
Same story as always: great topic, learned something along the way, unsatisfying conclusion with more questions left than I started out with and the nagging feeling of having to dig deeper. At some point...
Maybe...
Update: Quantized scaling
Michaud et al lead by Max Tegmark published a paper on "The Quantization Model of Neural Scaling" which actually might provide the tool to solve the issue outlined above!

This means, the quantification enables us to actually trace in quanta what happens within the model. With this we have the measurement unit and direction of learning that I deemed missing at the end of my post. Anything that helps to find a description that distinguishes between "individual neurons" (i.e., "too fine"), and individual capabilities (i.e., "too coarse") will help.
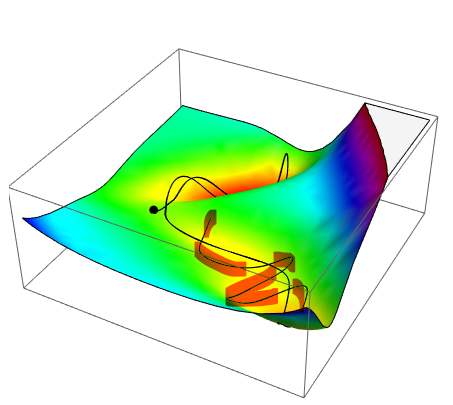
In addition, this allows to analytically retrace (within the network) the steps of learning in a 100% known lab-environment where every state of every neuron is fully described. Now you can describe each step of learning and add perturbations and check what influence it has on capability and speed of learning. Very exciting! Tegmark describes his lab as "artificial neuroscience". My past neuroscience-self is overjoyed because working with Zebrafish brains and other real living animals has many limitations. If you want to do some fundamental research on how knowledge is formed (at least in silico) you can now do it without the noise.
Bonus Video of C. Elegans whole brain recording from back in the days:
Sign up to the newsletter to get new posts straight to your inbox!